NMT-Keras¶
Neural Machine Translation with Keras.
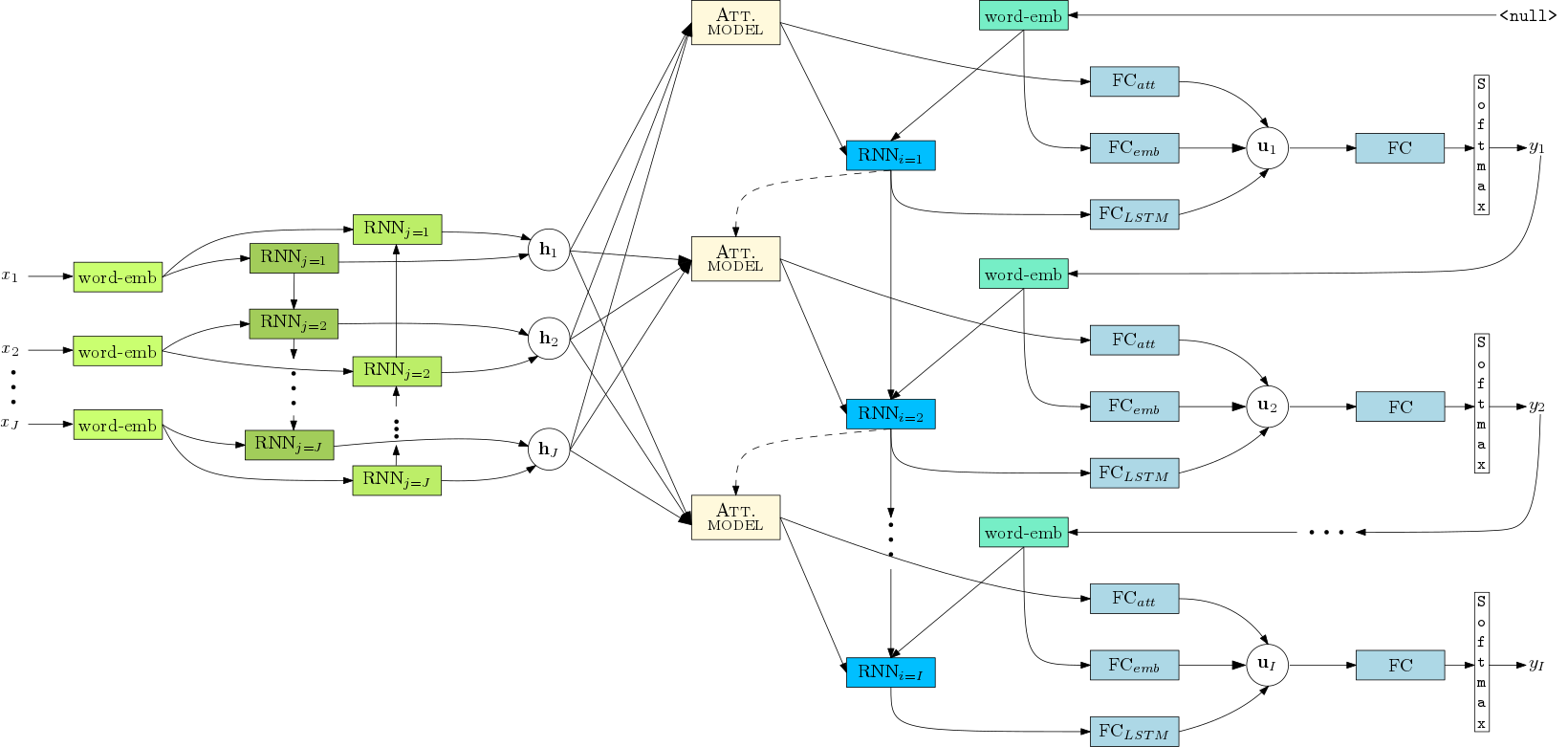
Features¶
- Attention RNN and Transformer models.
- Online learning and Interactive neural machine translation (INMT). See the interactive NMT branch.
- Tensorboard integration. Training process, models and word embeddings visualization.
- Attention model over the input sequence of annotations. - Supporting Bahdanau (Add) and Luong (Dot) attention mechanisms. - Also supports double stochastic attention.
- Peeked decoder: The previously generated word is an input of the current timestep.
- Beam search decoding. - Featuring length and source coverage normalization.
- Ensemble decoding.
- Translation scoring.
- N-best list generation (as byproduct of the beam search process).
- Support for GRU/LSTM networks: - Regular GRU/LSTM units. - Conditional GRU/LSTM units in the decoder. - Multilayered residual GRU/LSTM networks.
- Unknown words replacement.
- Use of pretrained (Glove or Word2Vec) word embedding vectors.
- MLPs for initializing the RNN hidden and memory state.
- Spearmint wrapper for hyperparameter optimization.
- Client-server architecture for web demos.
Guide¶
- Installation
- Usage
- Configuration options
- Naming and experiment setup
- Input/output
- Evaluation
- Decoding
- Search normalization
- Sampling
- Unknown words treatment
- Word representation
- Text representation
- Input text
- Output text
- Optimization
- Learning rate schedule
- Training options
- Early stop
- Model main hyperparameters
- AttentionRNNEncoderDecoder model
- Transformer model
- Regularizers
- Tensorboard
- Storage and plotting
- Resources
- Tutorials
- Modules
- Contact